How I use multiple agents for CI/CD on a complex Kotlin Multiplatform Project
How my staff of Claude agents runs a full spec-driven development pipeline for Krill, my Kotlin Multiplatform IoT control system, with zero human labor on the implementation of features and fixes.
A staff of agents, and a year of foundation work that made them possible
I spent the last year building Krill — a Kotlin Multiplatform peer-to-peer IoT control system that runs on Linux and Raspberry Pi: Ktor server, Compose Multiplatform clients, KSP-driven code generation, an MCP server, a Pi4J GPIO daemon. It’s the kind of codebase that makes you want to write more code, because it’s a pleasure to work with.
This is about how I use multiple Claude agents to run a full spec-driven development pipeline for Krill — with zero human labor on implementation. The agents handle everything from issue triage to testing to deployment while I focus on architecture.
The most important point up front: none of this would work without the foundation.
You cannot agent your way out of bad architecture. If your codebase has tangled dependencies, implicit coupling, untested seams, or “we’ll fix it later” debt in load-bearing places, then giving an agent the keys to it forces the agent to make architectural decisions every time it touches anything. Agents are bad at that. They make plausible-looking choices that compound into incoherence. The codebase rots faster, not slower.
With a consistent pattern, a new node type fits into Krill by gravity — there’s exactly one shape it can take. The architecture is the prompt. The codebase is the spec. That consistency is what makes agentic development possible.
Meet Ghost and Blue


Two GitHub bot accounts, two distinct identities. Ghost tests; Blue fixes. They have their own PATs, avatars, email addresses, and timeline presence.
Note: These are clearly-marked bot accounts, compliant with GitHub’s Terms of Service. They are tools for managing my projects efficiently, not attempts to deceive or impersonate.
Ghost runs in an intentionally empty sandbox with no preloaded knowledge of the Krill codebase. Ghost interacts with the running swarm only through the krill skill and its MCP server — the same way a brand-new user would. When Ghost stumbles, that’s the value: it surfaces friction a real first-time user would hit. Ghost’s job is to find the gap between what the skill says to do and what actually happens, and file that gap as a structured GitHub issue with the right repo, labels, and severity.
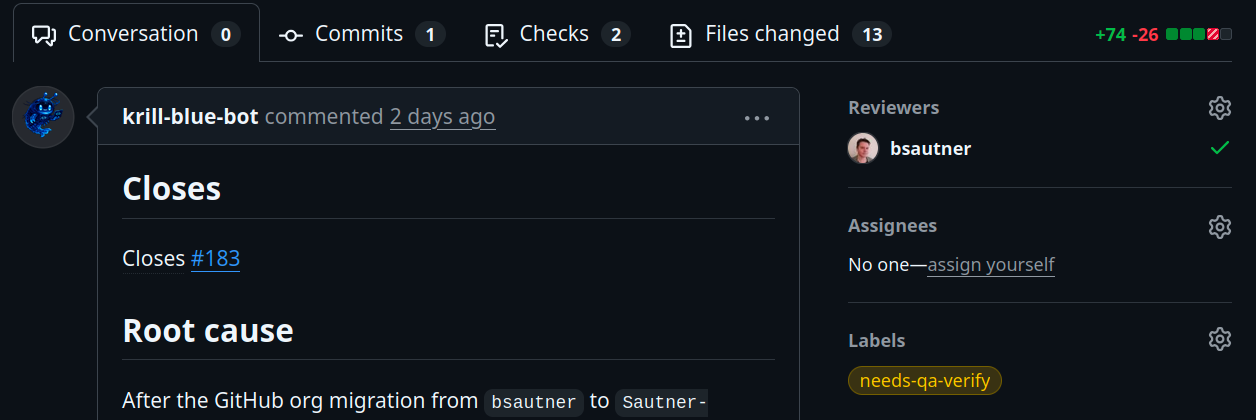
Blue doesn’t go looking for work — Ghost assigns it. When Ghost files an issue with assignee: krill-blue-bot, Blue’s polling loop picks it up. Blue reproduces locally, runs git log -S and git blame to find the introducing commit, writes a failing test, fixes it, adds a lessons entry to docs/lessons/, opens a PR, and tags it needs-qa-verify.
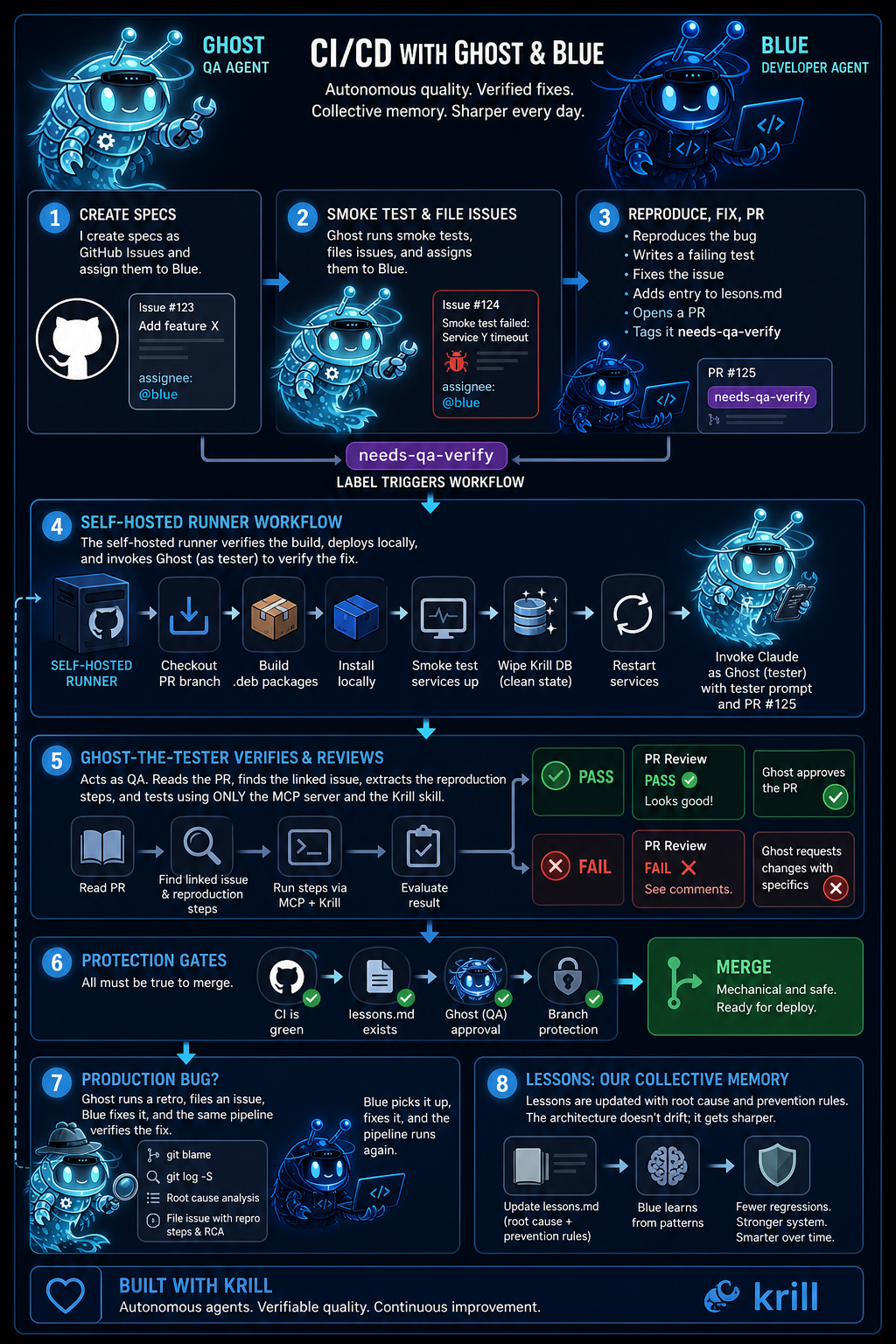
The verify loop
The needs-qa-verify label triggers a workflow on a Raspberry Pi self-hosted runner. The runner checks out the PR branch, builds the deb packages, installs them locally, smoke-tests that the services come up, wipes the local Krill database, restarts the services, and then invokes Claude as Ghost-the-tester with the PR number. Ghost reads the PR, finds the original issue, extracts the reproduction script, and runs it against the freshly-installed code. PASS or FAIL gets posted as a PR review.
Branch protection requires Ghost’s approval. Blue cannot merge his own work. CI must be green. The lessons file must exist. Once those gates clear, the merge is mechanical — and a deploy workflow publishes the debs to my apt repo. Twenty minutes from “Blue opened a PR” to “the fix is running in my house,” with zero copy-paste from me.
No single agent can corrupt the pipeline because no single agent owns more than one link.
What “better every cycle” actually looks like

Each fix Blue ships includes a lessons entry: what happened, the fix, and prevention as generalizable rules. CI rejects PRs that don’t include one. Over months, docs/lessons/ has become Krill’s collective memory of every regression. When Blue starts a new fix, the lessons file teaches him patterns to avoid.
The QA skill itself improves the same way. When Ghost files a qa-skill-gap issue — meaning the skill led a first-time user astray — Blue’s fix updates the skill in place. The next QA session uses the improved skill. Ghost gets less confused about the same things. Friction reduces over time.
The pause-and-wait pattern
The thing I didn’t expect, and that has done more for my trust than anything else: Blue stops.
Spec-driven development with agents isn’t “give the AI a goal and let it run.” It’s “give the AI a structured task with explicit boundaries, and design the boundaries to fail safely.” When Blue hits a question that exceeds the scope of an issue, Blue doesn’t decide. Blue asks.
A recent PR comment from Blue: “Two follow-ups left on the queue — stale org references in several files. Issue #36 explicitly bounded scope, so these need a separate PR. Want me to file the cleanup as its own issue while CI runs?”
That’s not me writing. That’s Blue asking a policy question and offering options. The right answer was “file the chore issue and hold.” If I’d said “fix it inline,” I’d have been teaching Blue that scope is negotiable, and the next PR would have three uninvited cleanups. So I said no, and Blue filed the chore issue.
This is what a well-mentored junior engineer does. They know when they don’t know.
The reason Blue stops is that the prompts make stopping the safe default: Never merge your own PR. Never close a QA issue without an explicit PASS. Never edit code outside your owned repo. Hard rules, not soft preferences. The agent hits a wall and asks rather than guesses.
I get those questions in the PR thread, on my phone, in the garden. I answer in 30 seconds. Blue moves on. I go back to the dogs.
What I do now
I architect. I make the calls Blue can’t make. I read the lessons directory to spot emerging patterns — three serialization regressions in a month means I need to tighten the contract. I decide what the next feature is and write the spec.
Mostly, though, I’m in the garden. My dogs — Lev and Po, shepherd-pit mixes — figured out months ago that “Ben checking his phone” now means Ben stays outside longer.
This is not the future of software engineering. It’s the future of senior software engineering. The agents are mine because the codebase is mine, the patterns are mine, and the lessons file is mine — all written in a form they can read and follow. They are not replacements. They are amplifiers, and amplifiers only work on a clean signal.
Anyone who skips the foundation to jump straight to agents will discover the agents accelerate whatever direction they’re pointed in. Pointed at a clean architecture, they make it cleaner. Pointed at a swamp, they help you sink faster.
Build the foundation. Then bring on the staff. Then go to the garden.